
Stepwise regression: a bad idea!
As insist in another post, the problems of stepwise regression can be resumed perfectly by Frank Harrell:
- The F and chi-squared tests quoted next to each variable on the printout do not have the claimed distribution.
- The method yields confidence intervals for effects and predicted values that are falsely narrow; see Altman and Andersen (1989).
- It yields p-values that do not have the proper meaning, and the proper correction for them is a difficult problem.
- It gives biased regression coefficients that need shrinkage (the coefficients for remaining variables are too large; see Tibshirani [1996]).
- It has severe problems in the presence of collinearity.
- It is based on methods (e.g., F tests for nested models) that were intended to be used to test prespecified hypotheses.
- Increasing the sample size does not help very much; see Derksen and Keselman (1992).
- It allows us to not think about the problem.
- It uses a lot of paper.
In this article, together with going into the mathematical details, we use simulation as a tool to demonstrate the defects of stepwise regression, a widely used technique by GLM practitionners.
Intuitive explanation
In my first lesson at the university, feature selection was about the p-value. Then digging a little bit deeper, I discovered stepwise regression, an “automatic” feature selection algorithm widely used by GLM practitionners. It was a huge progression to me at that time. Then inquisitively, wanting to learn more about this algorithm, I came to Cross Validated’s [stepwise-regression] tag, and suprisingly there are an enomous amount of critism towards this algorithm. A decent explanation of this can be found at this comment by @gung. But I still want to add my two cents.
There are several things to be remarked:
- All the statistical measurement used by stepwise to select “appropriate” variables such as: AIC, BIC, p-value, …. are just the realisations of random variables, and they contain not only their intrinsic value, but also errors.
- In every data set, there will certainly always be something like a ghost relationship between some independent variables (IVs) and the dependent variables (DP), even in the situation in which there is no relationship. Why? the relationship between IVs and DP seen in a single data set contains at the same time the intrinsic value and the errors just as before.
- The traditional hypothesis testing is supposed to test a single hypothesis by first devising a specific hypothesis as to the underlying causality. Not talking about the mistaken results by hypothesis testing (the significance), the pre-requisite of this test is notably violated by stepwise regression.
OK all of that seems to be complicated, let’s take an simple example: Prosecutor’s fallacy
Suppose that the probability that two people having the same DNA is 1/10 000. Then:
- If the DNA sample is found in the crime scene, and
- If a single specific man is acused
the probability of this man having the DNA matching with the criminal DNA is 1/10 000. This value of probability is proper to help concluding if this specific man is criminal or not.
But if, the criminal DNA is used to compare with the sample of 20 000 men, then, the probability of finding the matching DNA is:
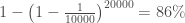
So in this case, if we find a person with his DNA matching the criminal DNA, his probability of crime is not 
This resumes exactly (but not all) the problem of stepwise regression. By searching many combination of candidate variable, this algorithm make the value of the statistics like p-value, AIC, BIC out of their propper meaning. It results in the p-value that is too small, the confidence interval that is too narrow, and AIC, BIC that are too good to be true.
Another explanation of the fallacy of stepwise can be resumed by data dredging:
the use of data mining to uncover patterns in data that can be presented as statistically significant, without first devising a specific hypothesis as to the underlying causality. The process of data mining involves automatically testing huge numbers of hypotheses about a single data set by exhaustively searching for combinations of variables that might show a correlation. Conventional tests of statistical significance are based on the probability that an observation arose by chance, and necessarily accept some risk of mistaken test results, called the significance. When large numbers of tests are performed, some produce false results, hence 5% of randomly chosen hypotheses turn out to be significant at the 5% level, 1% turn out to be significant at the 1% significance level, and so on, by chance alone. When enough hypotheses are tested, it is virtually certain that some falsely appear statistically significant, since almost every data set with any degree of randomness is likely to contain some spurious correlations. If they are not cautious, researchers using data mining techniques can be easily misled by these results.
Illustration
Data simulation
Let’s first build a data base for our experiment, which consists of an dependent variable (DV) and 50 candidate variables (IP), the DB and IPs were generated independently (i.e no relation ship between DV and IVs).
library(MASS)
set.seed(1)
nsim=10
#specify the number of IPs and number of observations
IP_nb=50
obs=3000
#simulating the IPs
X = matrix(0,nrow = obs,ncol = IP_nb)
for (i in 2:ncol(X)){
X[,i] = runif(nrow(X))
}
#Simulating the DP, independent from the IPs
X[,1] =rnorm(nrow(X))
#final data base
data=data.frame(X)
Building stepwise regression
Let us build a stepwise regression on this data set through three methods, backward, forward and both. And see how it behaves.
We need first to define the min and the max model
#defining the min model and the max model min.model = lm(X1 ~ 1, data=data) biggest = formula(lm(X1~.,data))
Forward
And lets test first the forward strategy using AIC as the selection criteria. The funciton
fwd.model = stepAIC(min.model, direction='forward', scope=biggest,trace=0) summary(fwd.model)

As you can see on the results of the forward selection strategy using AIC as indicator, 11 variables are considered as significant with the p-value that are too small, the confidence intervals that are too narrow to be true, while none of these variable has a relationship with the DP. This happens because: as in the example above, if we use the F or Chi-squared tests to test against only one pre-specified hypothesis (i.e one pre-specified variable / one cut-off, or pre-specified regrouping of the IPs), the p-value is correct. But if we use data mining to search over all the possibilities (like the example with 20 000 DNA being test), the p-value quoted next to each variable is calculated forgetting the phantom degree of freedom. In this case, all the other statistics are highly biased as well, such as standard error, AIC, BIC, … (note that AIC is equivalent to the p-value test with the significance level of around 15%). Of course the problem is less serious when we have more data.
Backward
One can argue that the forward is not the best stragegy because it doesn’t take into account the impact of the presence of one variable on the significance of the other variables. We can try the backward strategy:
#Backward elimination biggestBWD = lm(X1~.,data) bwd.model = stepAIC(biggestBWD, direction='backward',trace=0) summary(bwd.model)

Both
One can still argue that the backward strategy is not perfect because it doesn’t take into account the fact that adding one varialbe can make other variable insignificant. We can test the strategy combining forward and backward at the same time:
#Combination of backward and forward both.model=stepAIC(biggestBWD, direction='both',trace=0) summary(both.model)

Generalisation
The results of 10 000 simulations generating 10 000 different data bases using 3 different stepwise strategies can be sumarized in the following graphs: 
In none of the simulation, stepwise regression is able to find the true model. The average number of predictors selected are 10, while none of the candidate predictors has a relationship with the DP. Thus it results in serious overfitting.
Conclusion
Two problems of stepwise regression using AIC are adressed in this study:
- Serious overfitting.
- Biased statistical measurements (p-value, confidance intervals,AIC, BIC, ….) that are too good to be true because of data dredging.

One thought on “How bad is stepwise regression?”